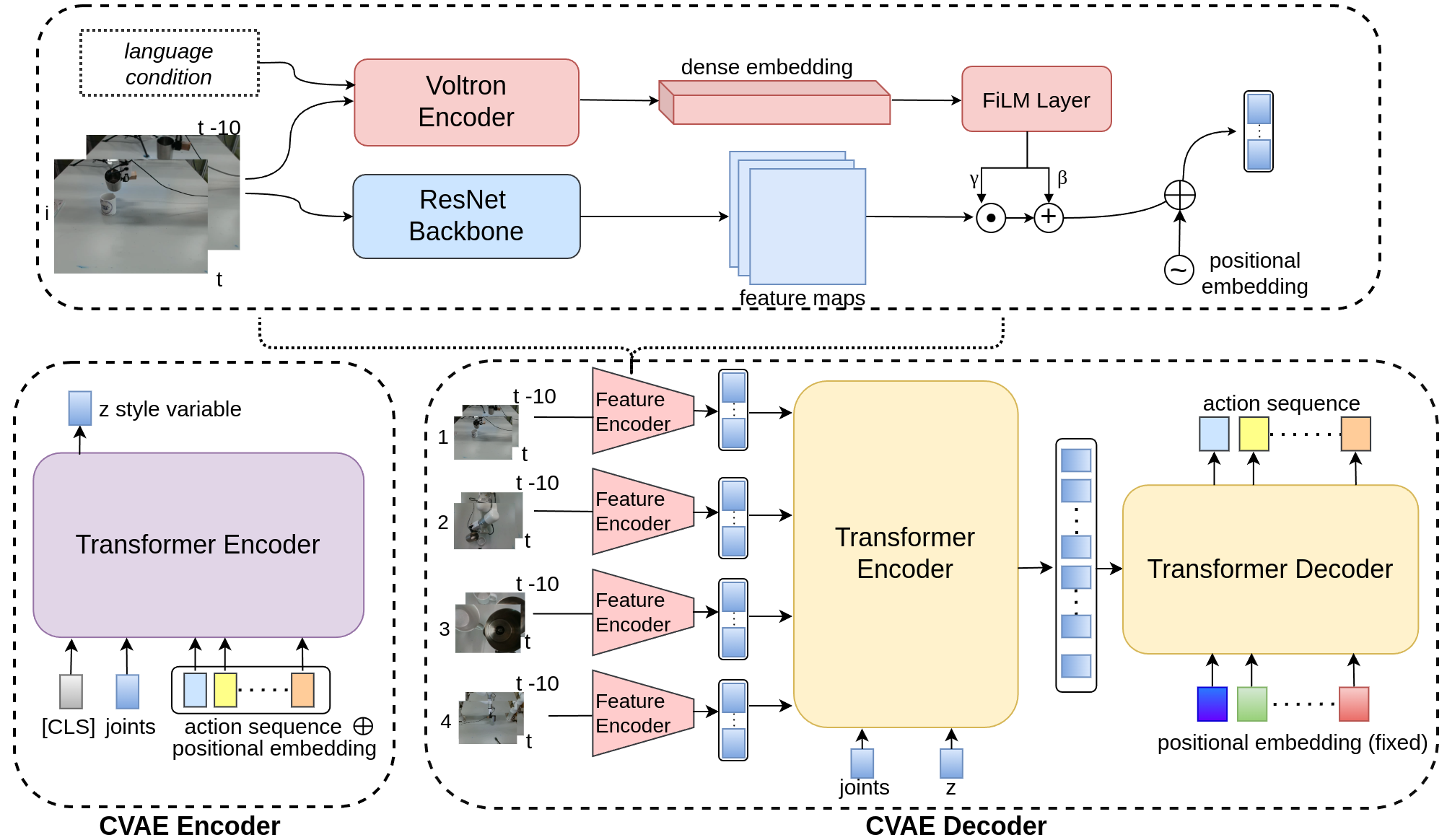
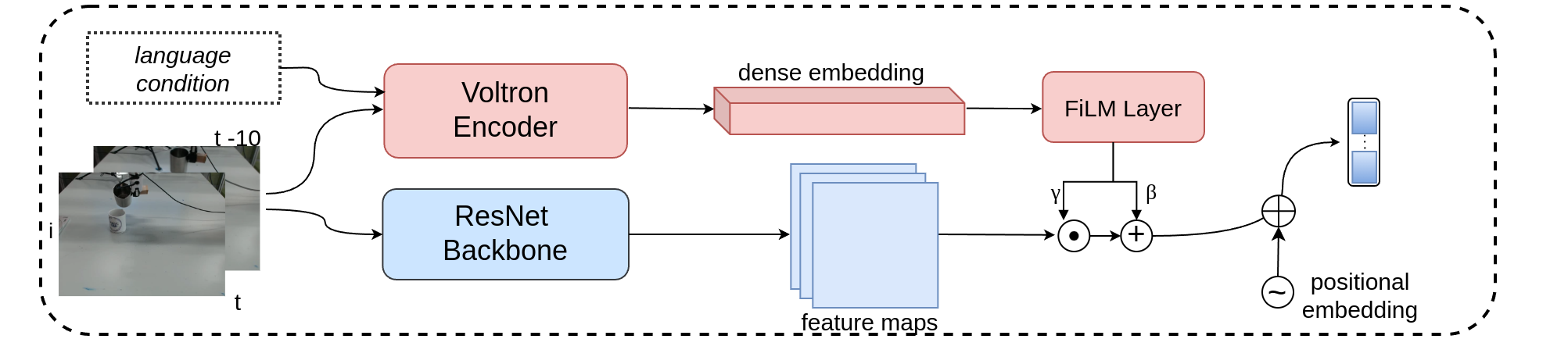
1. Language-Driven Dense Vector Encoding
We introduce a language-driven system to bimanual robotic arm manipulation by integrating the Voltron vision-language encoder.
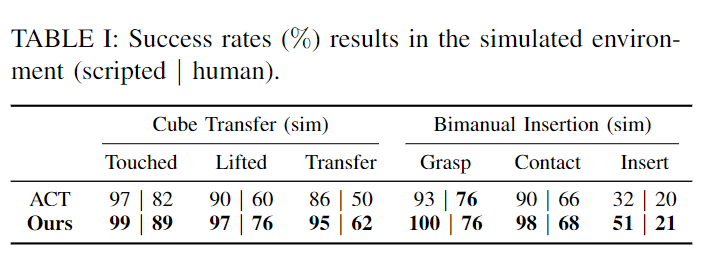
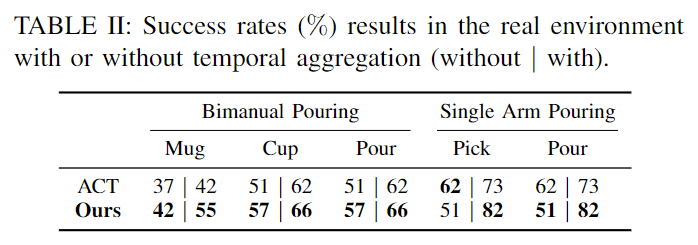
Bimanual robotic manipulation, involving the coordinated use of two robotic arms, is essential for tasks requiring complex, synchronous actions. Action Chunking with Transformers (ACT) is a representative framework that enables robots to break down complex tasks into manageable sequences, facilitating autonomous learning of multi-step actions. However, we observe critical limitations in the ACT framework: it relies solely on visual observations as input, focusing on task-specific action predictions, and it uses a simple ResNet-based feature extractor for image processing, which is often insufficient for complex and multi-view bimanual arm observations. In this paper, we introduce an enhanced language-driven version of ACT that leverages Voltron—a language-driven representation model—to incorporate both visual observations and language prompts into dense, multi-modal embeddings. These embeddings are used to condition the ResNet backbone feature maps through Featurewise Linear Modulation (FiLM), allowing our model to integrate contextually relevant linguistic information with visual data for more adaptive action chunking. Extensive experiments show that our approach significantly improves the performance of bimanual robot arms in executing complex, multi-step tasks guided by language cues, outperforming traditional ACT methods.
We introduce a language-driven system to bimanual robotic arm manipulation by integrating the Voltron vision-language encoder.
We propose integrating Voltron to condition the ResNet backbone feature maps through Feature-wise Linear Modulation (FiLM), enabling the model to combine linguistic context with visual data for more adaptive action chunking.

Find all the trainig data in this link: (coming soon)
@INPROCEEDINGS{10977578,
author={Tripathi, Dhurba and Liu, Chunting and Pudasaini, Niraj and Hao, Yu and Tzes, Anthony and Fang, Yi},
booktitle={2025 11th International Conference on Automation, Robotics, and Applications (ICARA)},
title={LAV-ACT: Language-Augmented Visual Action Chunking with Transformers for Bimanual Robotic Manipulation},
year={2025},
volume={},
number={},
pages={18-22},
keywords={Visualization;Adaptation models;Robot kinematics;Modulation;Linguistics;Transformers;Manipulators;Feature extraction;Data models;Context modeling;Imitation Learning;Bimanual Manipulation;Behavior cloning},
doi={10.1109/ICARA64554.2025.10977578}}